菜单
首页财产ai正文 Opus 4.7 压根没想做「最强模子」 2026年4月16日,Anthropic发布Claude Opus 4.7,其编程、视觉能力有晋升,但长上下文等能力退步,是一次有明确弃取的迭代。 2026-04-17 14:26 ·微信公家号:硅星人Opus 4.7 AI投资人解读· Opus 4.7于编程能力、视觉能力上有显著晋升,于金融法令常识事情方面领先。· 长上下文能力及搜刮能力退步,tokenizer变动等致使现实成本上升,对于指令解读更字面化。总结:Opus 4.7有前进也有弃取,晋升了编程与视觉能力,却于长上下文等方面退步,利用成本增长。虽非“最强模子”,但表现Anthropic产物计谋调解,投资时需综合多方面因素评估其潜力与危害。内容由AI天生,仅供参考
2026 年 4 月 16 日,Anthropic 正式发布 Claude Opus 4.7,间隔上一代 Opus 4.6发布仅两个多月。
于近来一阵密集而疯狂的产物与模子更新后,抛出新模子的Anthropic天然给人一种放年夜招的觉得。想必你也已经经看到许多*时间的模子陈诉梳理,各个把Opus 4.7称为“最强模子”,那些“人类完了”、“掉业预警”等等再次刷屏。
但还有是要看看Anthropic本身发了啥吧。
此次发布的基调实在不太平常。
Anthropic 于通知布告里直接写道:Opus 4.7的能力不如 Claude Mythos Preview——而 Mythos 只对于 Apple、Google、Microsoft、Nvidia 等少数互助伙伴开放,平凡开发者及用户没法利用。
同时,比它的这类说辞更值患上存眷的, 是它不只是比传说中的Mythos更弱,它实在比上一代模子,也于要害的一些能力上更弱。
Opus 4.7自己那份跑分内外的一个异样数字:长上下文基准 MRCR v2 @1M 从 Opus 4.6的 78.3% 跌到 32.2%,46 个百分点的狂跌。
很少有旗舰模子迭代会把自家王牌能力砍失一半。
并且这是它自动做出的选择。
以是,当列位继承无脑惯性吹它的每个模子是“最强”的时辰,实在已经经跟不上Anthropic本身的节拍了!

它甚至都不care去改良一下这个洗车问题
Opus 4.7是一次底子没有想做成“最强模子”的发布,它是一次有明确弃取的,“精准刀法”式的发布,与以往头部模子厂商的各类发布思绪都差别,也是今天头部厂商于明确感触感染到模子自己的“年夜跃进”再也不可连续后,会团体转向的新标的目的——Anthropic某种水平上已经经于向苹果、微软等公司于他们很是成熟的产物贸易化阶段的发布计谋挨近。
这可能才是4.7的真正主要之处。
1、编程能力:数字暗地里的真实改善
要更好理解这些变化,*的方式天然是先细心看一下它此次到底发了甚么。
如下是 Opus 4.7此次发布的完备信息梳理——哪里前进了、哪里摆烂了、开发者一手反馈是甚么、该不应迁徙。
官方通知布告:https://www.anthropic.com/news/claude-opus-4-7
Opus 4.7的编程成就是此次发布的主轴。
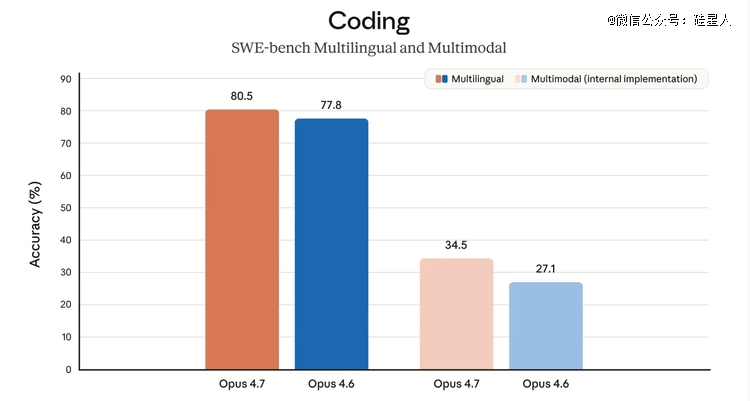
SWE-bench Verified(500 个真实 GitHub issue,模子需写出能经由过程测试的补钉)从 Opus 4.6的 80.8% 升至 87.6%,靠近 7 个百分点的晋升,是今朝公然可用模子中的*名。对于比 Gemini 3.1 Pro 的 80.6%,差距较着。
SWE-bench Pro是更难的版本,笼罩四种编程语言的完备工程流水线。Opus 4.7从 53.4% 升至64.3%,11 个百分点的跳升。对于比 GPT-5.4 的 57.7%、Gemini 3.1 Pro 的 54.2%,Opus 4.7于这项基准上较着*。
CursorBench是来自 Cursor 的实战基准,专门权衡模子于真实 IDE 情况中的编程辅助质量。Opus 4.6是 58%,Opus 4.7跳到了 70%,12 个百分点的晋升。Cursor 结合开创人 Michael Truell 于官方通知布告中说:"这是能力上的成心义跳跃,于解决难题时有更强的创造性推理。"
互助伙伴实测数据:
Rakuten:Opus 4.7解决的出产使命数目是 Opus 4.6的3 倍,代码质量及测试质量评分都有两位数晋升
Factory:使命乐成率晋升 10-15%,模子半途停下来的环境较着削减
Cognition(Devin 暗地里的公司):模子"可以持续事情数小时而不失线"
CodeRabbit:召回率晋升跨越 10%,"比 GPT-5.4 xhigh 模式略快"
Bolt:于较长的运用构建使命上,Opus 4.7比 Opus 4.6"*环境下晋升 10%,没有已往那种退步问题"
Terminal-Bench 2.0:Opus 4.7解决了三个以前没有任何 Claude 模子(或者竞争敌手)能处置惩罚的使命,此中一个是需要跨繁杂代码库多文件推理才能修复的竞争前提(race condition)

这些数据集中指向一个标的目的:Opus 4.7于长周期、跨文件、需要连结上下文联贯的繁杂编程使命上有较着改善。这恰是 Opus 4.6用户于已往两个月吐槽至多的点——使命履行到一半就主动抛却、碰到多文件 bug 就迷掉。
2、视觉能力:此次发布最被低估的改良
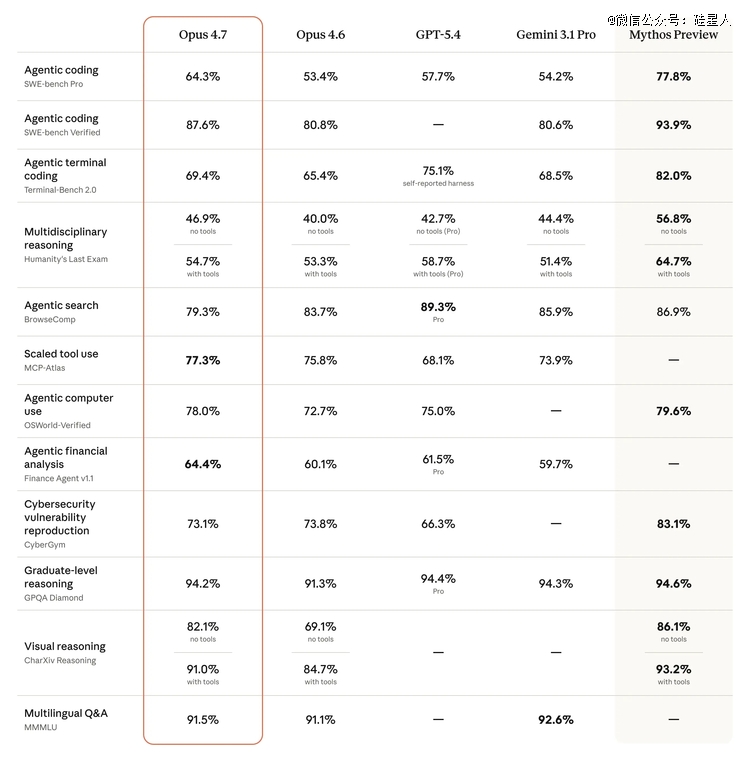
视觉精准度基准XBOW 从 54.5% 跳到 98.5%。这不是渐进式改良,是重修级另外跃迁。
详细规格变化:
*图象分辩率从约 115 万像素(长边 1,568 像素)晋升至约375 万像素(长边 2,576 像素),是前代的 3 倍多
模子坐标与现实像素实现1:1 对于应,此前 computer use 使命需要手动换算缩放系数,此刻这个步调消散
CharXiv 视觉推理基准:不带东西 82.1%,带东西 91.0%
这对于哪些场景有本色影响?
对于 computer use 产物团队来讲,此次进级多是决议性的。Opus 4.6时代的 computer use 处在"能做 demo 但不敢上出产"的状况——误点率过高,难以猜测。98.5% 的视觉精准度象征着这个功效*次具有了靠得住部署的门坎。多家技能博客于评测里直接写道:假如你由于 Opus 4.6误点频率过高而弃捐了 computer use 产物规划,4.7断根了这个障碍。
Reddit 上的一手反馈(r/ClaudeAI):有效户提到,"视觉能力的晋升太要害了,我以前做了许多边沿项目,测验考试让模子于视觉反馈轮回里迭代改良输出,效果一直很杂乱,很期待 4.7能怎么处置惩罚这个问题。"
除了 computer use 外,受益的场景还有包括:扫描文档阐发(能读取更小字体、辨认更邃密的图表细节)、截图理解、仪表盘类运用、繁杂 PDF 处置惩罚。
需要留意的成本问题:更高分辩率的图象会耗损更多 token。假如你的运用场景对于图片细节要求不高,建议于传入前先降采样。
3、*的退步:长上下文崩了
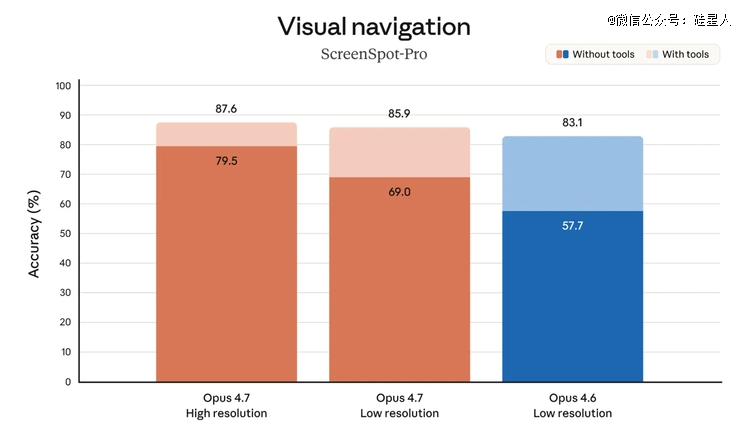
MRCR v2 @1M(百万 token 长上下文影象测试):
4.6:78.3%
4.7:32.2%
狂跌 46 个百分点,从靠近 80% 直接失到三分之一。
这个跌幅于旗舰模子迭代史上险些没有先例。MRCR v2 是 Anthropic 本身于 Opus 4.6时代被重点宣传的能力——其时Anthropic 的原话是"于一个模子现实能用的上下文量级上发生了质变"。到 4.7,这个"质变"直接消散了。
为何会如许?Tokenizer 换了。
Opus 4.7利用新的 tokenizer,一样的输入文本会孕育发生约1.0-1.35 倍的 token 数目,详细倍数因内容类型而异。
直接连锁反映是:
名义上 200K/1M 的上下文窗口还有于,但一样的文字能装的量少了
长使命 agent 事情流的现实 token 耗损增长约 35%
订价没变(输入 美金五、输出 美金25 每一百万 token),但现实利用成本上升
Anthropic 的官方说法是新 tokenizer"晋升了文本处置惩罚效率",但 benchmark 数据显示于长上下文场景下是较着退步的。
搜刮能力也退步了:
BrowseComp(收集深度信息检索):Opus 4.6的 83.7% → Opus 4.7的 79.3%
GPT-5.4 Pro 于这项上患上分 89.3%,Gemini 3.1 Pro 患上 85.9%,Opus 4.7今朝于重要竞争模子中垫底
搜刮及长文本,偏偏是许多企业用户最经常使用的场景。
Hacker News 上开发者的一手反馈(帖子 275 赞、215 评论,来历:HN 会商):
"关失 adaptive thinking、把 effort 手动拉到最高,才让我回到基线体现。'咱们内部评测看起来不错'这类说法此刻已经经不敷了,各人都看到同样的问题。""4.7默许再也不于输出里包罗人类可读的推理 token 择要,必需于 API 哀求里加 display: su妹妹arized 才能拿回来。"
这些都是现实利用者反应的问题。但这也是Anthropic本身自动做出的选择。
4、新的举动特性:自我验证与更字面化的指令追随
Opus 4.7官方通知布告里有一句值患上零丁拎出来:模子于上报成果以前会核验本身的输出。
Hex 的技能团队于测试中给出了一个详细案例:当数据缺掉时,Opus 4.7会照实陈诉"数据不存于",而不是给出一个看上去合理但现实是编造的谜底——尔后者恰是 Opus 4.6会踩的坑。金融科技平台 Block 对于此的评价是:"它于计划阶段就能发明本身的逻辑过错,加快了履行速率,比以前的 Claude 模子有较着逾越。"
但自我验证带来了另外一个连带的举动变化:Opus 4.7对于指令的解读更字面化。
这是一个主要的迁徙危害。假如你为 Opus 4.6精心调过 prompt,4.7可能不会像 4.6那样"读出言外之意",而是严酷根据你写的字面意思履行。Anthropic 于官方迁徙指南里明确提到了这一点,建议上线 4.7前对于要害 prompt 做回归测试。
一个实用参照数字来自 Hex 的 CTO:低 effort 档的 Opus 4.7,机能约莫等在中 effort 档的 Opus 4.6。
5、推理节制机制:xhigh、task budgets 及 /ultrareview
Opus 4.6发生过一件影响用户信托的事:2 月 9 日切换到自顺应思索默许模式,3 月 3 日官方又把 Claude Code 的默许推理深度从最高等调至 medium,理由是"于智能、延迟、成本之间取患上均衡"。这件事被用户称为"降智门",AMD 一名高级总监于 GitHub 的质疑帖被广泛转发。
Opus 4.7给出的回应是,把推理深度的节制权更显式地交给用户。
xhigh effort 档:新增的推理强度级别,位在原本的 high 及 max 之间。Claude Code 此刻已经经把所有规划的默许档位更新为 xhigh。
但开发者社区对于 xhigh 有一个直接疑难,Reddit 用户的原话是:"Opus 4.6默许是 medium,4.7默许是 xhigh。我想知道这个决议计划暗地里的思量,由于 effort 档提高显然会带来更多的 token 耗损。"
换句话说:用户看到的是一次"把节制权交还有给用户"的修复,但现实上默许档被拉高了,象征着一样的使命要烧更多 token。叠加 tokenizer 变动,这是两重的成本晋升。
task budgets(公测中):针对于长使命的 token 预算节制机制。开发者设置一个总 token 预算(* 20K),模子于履行历程中能及时看到残剩额度,据此分配资源,防止跑到一半由于 token 超支停下来,也避免没必要要的计较华侈。
Claude Code 新增 /ultrareview 号令:专项代码审查会话,运行一次专注在 bug 排查及设计问题的深度审查,Pro 及 Max 用户每个月赠予 3 次免费利用。
auto 模式对于 Max 用户开放:此前只于 Enterprise 规划里有,此刻 Max 用户也能用。Claude 于 auto 模式下可以自立做决议计划、削减半途扣问用户的次数。Claude Code 团队卖力人 Boris Cherny 的原话是:"给 Claude 一个使命,让它跑,回来看已经经核验过的成果。"
6、跑分全景:哪里赢了,哪里输了
如下是今朝已经宣布的重要基准数据(来历:Anthropic 官方 system card 和互助伙伴评测)。
编程与工程类(Opus 4.7*)
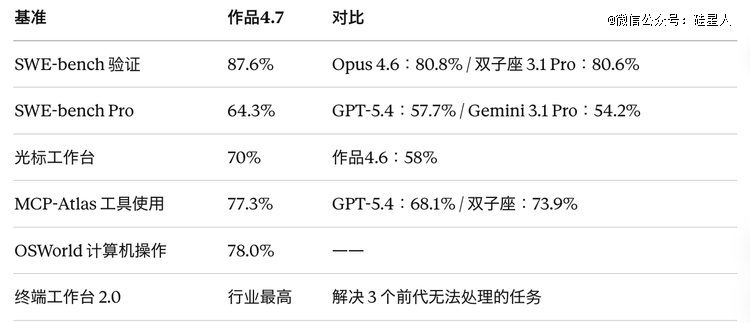
视觉与多模态(Opus 4.7年夜幅*)
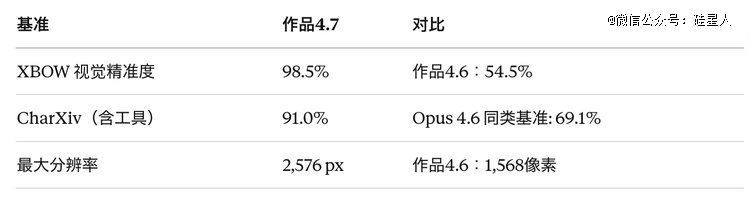
常识事情(Opus 4.7*)
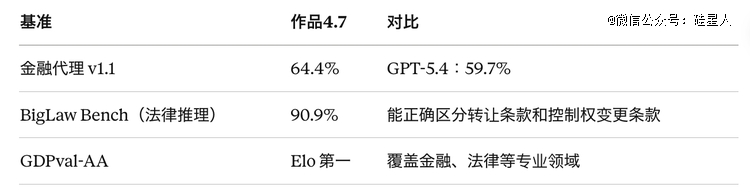
综合评测(Opus 4.7较着上台阶)

通用推理(三家基本打平)

这个基准已经趋在饱及,再也不是有用的竞争分水岭。
研究类使命(GPT-5.4 *,Opus 4.7退步)

长上下文(Opus 4.7年夜幅退步)

总结选型逻辑:编程、工程 agent、视觉、金融法令常识事情四块 Opus 4.7有明确上风;研究密集型使命及开放式收集检索 GPT-5.4 更强;长上下文场景下 Opus 4.7比本身的前代还有差一年夜截,这是最值患上警惕的点。
7、安全护栏:Mythos 的铺路石
这部门轻易被看成发布稿里的"安全例行声明"跳过,但它是理解 Anthropic 当前战略的要害。
4 月 7日,Anthropic 公布了 Project Glasswing:把 Claude Mythos Preview 开放给 Apple、Google、Microsoft、Nvidia、Amazon、Cisco、CrowdStrike、JPMorgan Chase 及 Broadcom 九家互助伙伴,专门用在防备性收集安全场景。
Mythos 是 Anthropic 迄今能力最强的模子,按照 The Hacker News 的报导,它能自立发明零日缝隙,于重要操作体系及阅读器里找出了数千个此前未知的缝隙。但正由于这个能力,它也被判断为带有庞大滥用危害,以是不公然发布。
Opus 4.7于这条线上是*个测试样本。Anthropic 于练习阶段自动减少了模子的收集安全进犯能力(同时只管即便保留防备能力),并上线了主动检测及阻挡高危害收集安全哀求的及时护栏体系。通知布告原文:"咱们将经由过程 Opus 4.7的现实部署来进修这套护栏是否有用,再决议是否把它推广到 Mythos 级另外模子上。"
换句话说,每一个用 Opus 4.7的开发者都于帮 Anthropic 标定安全护栏的界限。
Gizmodo 的评价:此次发布采用了"斗胆的营销计谋——自动宣传自家新模子'通用能力不如另外选择'",这于旗舰发布里极为稀有。
安全从业者假如需要将 Opus 4.7用在正当的渗入测试、缝隙研究或者红队测试,需要申请插手 Cyber Verification Program。
8、价格与迁徙:名义稳定,现实涨了
订价:输入 美金5/百万 token,输出 美金25/百万 token,与 Opus 4.6不异。API 模子 ID 为 claude-opus-4-7。可用平台包括 Claude API、Amazon Bedrock、Google Cloud Vertex AI、Microsoft Foundry,GitHub Copilot 也已经同步上线。
但正如前面提到的,tokenizer 变动让一样输入孕育发生约1.0-1.35 倍的 token 数,叠加更高默许 effort 档位下的思索 token,对于在长使命 agent 事情流,现实成本多是 Opus 4.6划一设置下的 2-3 倍。
Anthropic 同时把 Claude Code 的缓存 TTL 从一小时缩短到五分钟——这象征着假如你脱离电脑跨越五分钟再回来,上下文缓存掉效,患上从头加载,token 耗损会更快。Reddit 社区已经经有不罕用户吐槽"额度烧患上比瀑布还有快"。
对于现有 Opus 4.6用户的粉碎性变动清单:
Extended Thinking Budgets 参数已经移除了,传入会返回 400 过错,需改用 adaptive thinking 模式
温度(temperature)、top_p、top_k 等采样参数已经移除了,需用 prompting 节制输出举动
更严酷的字面化指令追随——为 Opus 4.6调好的 prompt 需要从头测试,不克不及直接换模子 ID 上线
tokenizer 变动致使 token 计数变化,建议先于真实流量上跑样本,再做完备迁徙
默许输出再也不包罗推理 token 择要,需要显式设置 display: su妹妹arized 才能拿回
实用建议:Anthropic 官方迁徙指南建议,正式切换前用代表性的出产流量跑 Opus 4.7,对于比 token 耗损及使命质量再做决议。
可以放出精准的刀法,最为可骇
Opus 4.7是一次有清楚靶向的进级,也是一次有较着价钱的进级。并且这些都是Anthropic本身设计好的,且很年夜水平上你必需为它买单。
这个模子前进的一壁:
SWE-bench Verified 的 87.6%、SWE-bench Pro 的 64.3%、CursorBench 的 70%、Rakuten 的 3 倍出产使命——这些是出产情况里能感知到的编程能力晋升
视觉能力重修(XBOW 54.5% → 98.5%、分辩率翻 3 倍、像素 1:1 对于应),让 computer use *次具有靠得住部署的门坎
xhigh 档位、task budgets、/ultrareview,是对于"降智门"的显式回应
BigLaw 90.9%、Finance Agent 64.4%,于金融法令这种专业常识事情上明确*
抛却的一壁:
MRCR v2 @1M 从 78.3% 跌到 32.2%,长上下文能力险些砍半
BrowseComp 从 83.7% 跌到 79.3%,搜刮能力被 GPT-5.4 及 Gemini 3.1 Pro 双双反超
tokenizer 变动 + 默许 effort 拉高 + 缓存 TTL 缩短 = 三重隐性涨价
Mythos 压着不放,象征着 Anthropic 手里还有有更强的牌但出不来
此次发布最真正的样子,不是"最强模子"也不是"最强公然模子",而是:一次有明确弃取的迭代。
最新的动静是,Claude Code 于 2 月的年化收入已经经到达 25 亿美元。Opus 4.7就是这条线上的下一个赌注。
编程及视觉是加法,长上下文及搜刮是减法,价格名义稳定但账单于涨。Anthropic 正于用 Opus 4.7做一次均衡——既要修复 Opus 4.6遗留的信托毁伤,又要为 Mythos 级模子未来的更年夜规模开放做安全护栏的实战练习训练。以和更主要的,它要充实使用好今天本身所处的*位置,把用户对于它产物的喜欢,转化为对于一代一代产物哪怕出缺陷却依然离不开的惯性,然后成立起像苹果等公司已经经进入成熟期才有的那种又爱又恨的用户粘性,及真正有贸易价值的生态。
【本文由投资界互助伙伴微信公家号:硅星人授权发布,本平台仅提供信息存储办事。】若有任何疑难,请接洽(editor@zero2ipo.com.cn)投资界处置惩罚。
-太阳集团tyc86