菜单
首页财产ai正文 Claude Opus 4.7突袭!Anthropic把「不乱猜」做成为了焦点卖点 本地时间4月16日,Anthropic发布Claude Opus 4.7,于多范畴测试中机能晋升,视觉智能前进显著,虽非最强但均衡了能力、安全与成本。 2026-04-17 14:14 ·微信公家号:钛媒体硅谷Tech news AI投资人解读· Anthropic发布的新一代旗舰模子Claude Opus 4.7专为繁杂使命设计,于多范畴基准测试中机能显著晋升,视觉智能前进较着,指令遵照能力晋升,还有更新了相干功效。 · token耗损增长致成本上升Anthropic限定其高级收集安万能力,计谋效果待察。 总结:Opus 4.7揭示出强盛实力与立异,于能力、安全、成本间寻均衡,虽有危害,但有望依附上风获市场承认,为AI行业成长提供新思绪,具有投资潜力,不外需存眷成本与安全计谋影响。内容由AI天生,仅供参考
本地时间4 月 16 日,Anthropic 正式发布新一代旗舰模子 Claude Opus 4.7。该公司将其定位为"迄今能力最强的通用可用模子",标记着人工智能行业竞争核心的决议性改变——从寻求对于话流利性转向查核自立使命履行能力。
与两个月前发布的 Opus 4.6 比拟,新版本专为Agentic事情流设计,即需要 AI 于较永劫间内自力运行、仅需极少量人类干涉干与的繁杂使命。这次更新优先晋升高分辩率视觉感知、繁杂多步软件工程链不变性,以和长上下文检索能力,而非纯真寻求推理深度(官方博客地址:https://www.anthropic.com/news/claude-opus-4-7)。
值患上留意的是,Anthropic 于发布 Opus 4.7 的同时坦诚暗示,这并不是其最强模子——能力更强的 Claude Mythos Preview 仍处在受限测试阶段。
一、视觉智能冲破与长上下文瓶颈霸占
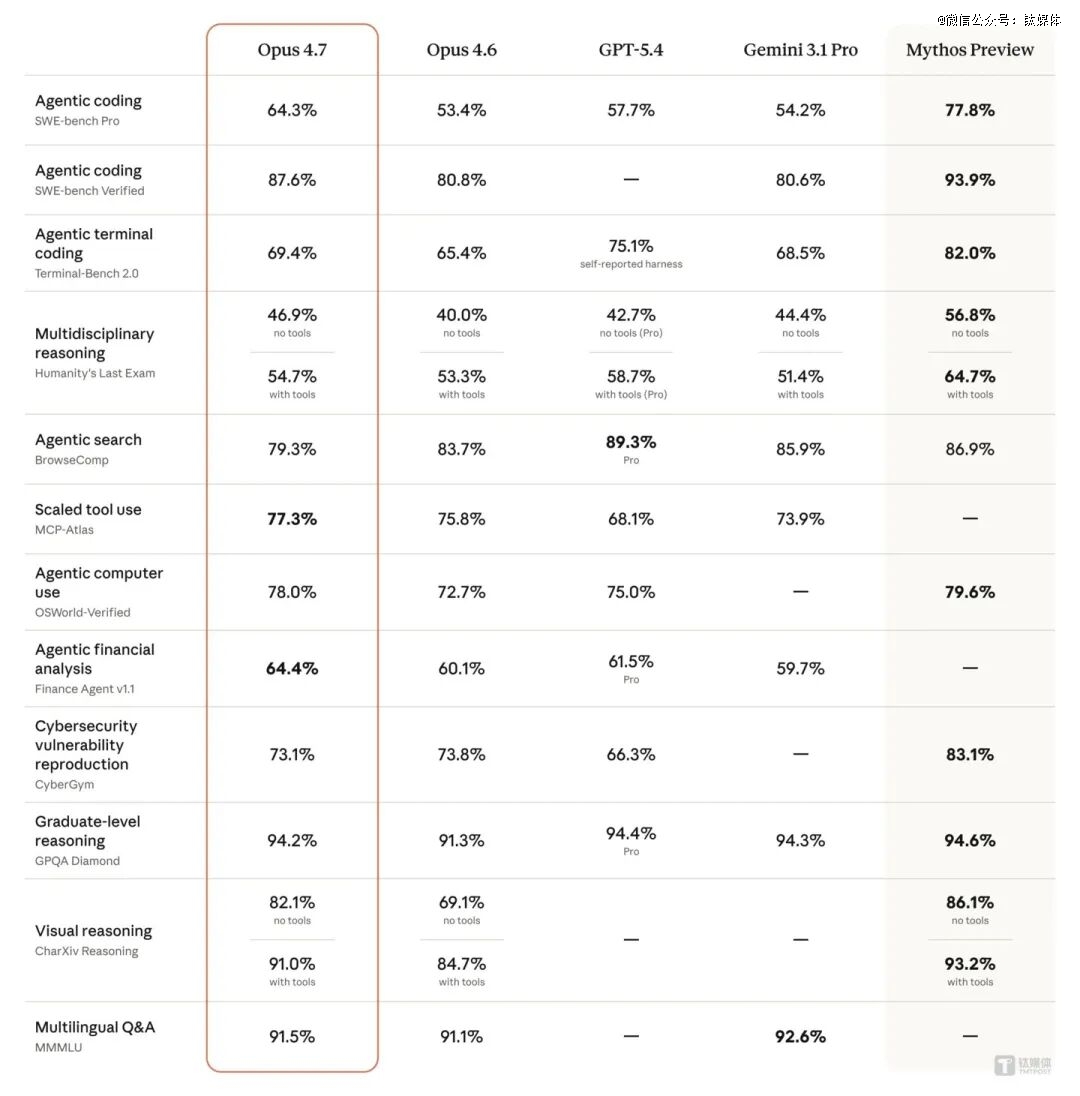
于企业级运用场景的基准测试中,Opus 4.7 与重要竞争敌手的机能差距进一步拉年夜。于 OfficeQA Pro 评测中——该评测由 Databricks 开发,要求模子解析近 9 万页美国财务部汗青文件(涵盖近 100 年公报、2600 万个数字)——Opus 4.7 取患上 80.6% 的患上分。这一成果险些是google Gemini 3.1 Pro(42.9%)的两倍,并年夜幅*在 GPT-5.4(51.1%)。数据显示,Anthropic 已经于长上下文检索的要害瓶颈上取患上冲破。
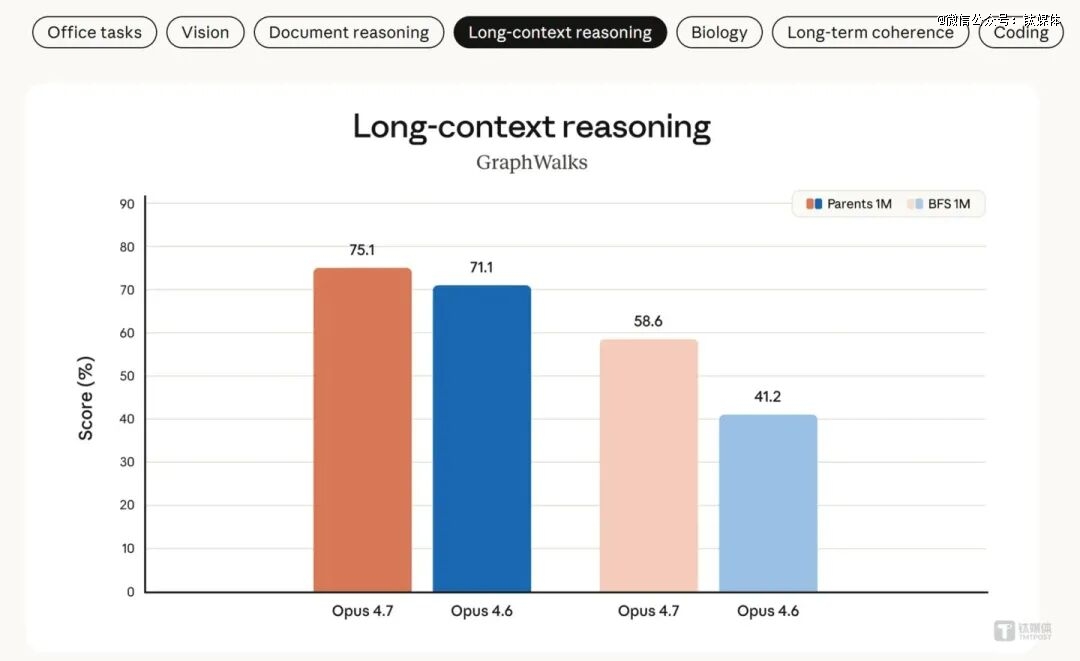
于 BFS 1M 测试中——该测试由 OpenAI 设计,将一张有向图用边列表塞满 100 万 token 上下文,要求模子举行图遍历——Opus 4.7 从 Opus 4.6 的 41.2% 晋升至 58.6%,晋升幅度达 17.4 个百分点。这项指标被视为权衡 AI 智能体(Agent)跑多步调长使命的硬性指标。于 Vending-Bench 2 模仿谋划测试中,Opus 4.7 终极实现 10,937 美元余额,较 Opus 4.6 的 8,018 美元晋升 36%,揭示出永劫间事情流中的决议计划联贯性上风。
视觉智能是此版本前进最为显著的方面。
Opus 4.7 此刻撑持最长边达 2,576 像素的图象输入,分辩率约 375 万像素,较前代晋升跨越三倍。这使患上模子可以或许"看到"屏幕上占比低至 0.07% 的 UI 元素。于 ScreenSpot-Pro 基准测试中——该基准评估 AI 于 VSCode、Photoshop、AutoCAD 等专业软件中定位特定按钮或者数据点的能力——Opus 4.7 于高分辩率模式下共同东西挪用功效到达 87.6% 的乐成率,而 Opus 4.6 于低分辩率下仅为 57.7%。
这类切确度再也不是纯真的学术摸索,而是"电脑利用"(Computer Use)能力的条件。Anthropic 将图象分辩率年夜幅晋升的素质目的,是让 AI 可以或许看懂软件界面、密集表格、终端输出、设计稿细节及代码截图。
将来 AI 办公、AI 测试、AI 安全、AI 前端开发等使命,都将从纯文本使命转向屏幕使命。于 SWE-bench Multimodal 测试中——该测试要求模子联合 UI 截图及代码一路修复前端 JavaScript bug——Opus 4.7 从 Opus 4.6 的 27.1% 晋升至 34.5%,晋升 7.4 个百分点。这注解视觉能力的进级直接办事在编程场景的现实需求。
Anthropic 于官方通知布告中尤其夸大,Opus 4.7 于指令遵照能力上呈现显著晋升。过往模子可能会宽松地"乱来"指令或者彻底跳过部门唆使,但 Opus 4.7 会严酷按字面意思履行指令。
这一变化带来两重影响:一方面,它削减了提醒词"形而上学",使写需求、定格局、列限定前提变患上越发靠得住;另外一方面,用户可能需要重写旧的、更偏对于话式的提醒词以免不测输出。很多用户的提醒词是于旧模子"会主动补全真实用意"的习气上调优出来的,而新模子的刚性可能致使这些旧提醒词掉效。
于高级软件工程范畴,这类严谨性转化为显著晋升。于 SWE-bench Verified 测试中,Opus 4.7 患上分为 87.6%,Opus 4.6 为 80.8%;于更难的 SWE-bench Pro 测试中,Opus 4.7 为 64.3%,Opus 4.6 为 53.4%。这象征着用户可以将已往需要紧密亲密监视的高难度编码事情交给 Opus 4.7 处置惩罚,它会于报告请示成果前自动验证自身输出。
Opus 4.7 于利用基在文件体系的影象方面体现更为精彩。它能于永劫间、多会话的事情中记住主要条记,并将其用在开展新的使命,是以新使命需要更少的前置上下文。一个能跨会话记住项目约束、用户偏好、架构决议计划及前次掉败缘故原由的 Agent,才可能从"智慧姑且工"酿成"不变同事"。这一特征于官方通知布告中其实不显眼,但多是持久利用中最要害的更新。
陪同 Opus 4.7 发布,Anthropic 还有更新了 Claude Code,新增 auto mode 及/ultrareview 功效。auto mode 不是模子主动选型,而是权限选项。它答应 Claude 替用户做一些权限决议计划,让长使命少被打断,但危害低在彻底跳过权限确认。
这个设计针对于的是 Agent 产物的焦点抵牾:问太多,Agent 像实习生;不问,危害又太年夜。auto mode 的素质,就是于"别烦我"及"别糊弄"之间找均衡。/ultrareview 是一个专门的代码审查会话,可读取变动并指出 bug 及设计问题。
这标记着 AI 编程正式进入第二阶段:让 AI 本身审查 AI 本身天生的代码。天生代码只是开发流程的一部门,审查、测试、重构、文档一样主要。假如 AI 只能做*步,它永远只是辅助东西;假如它能介入整个流程,它才可能真正转变软件开发的方式。
二、专业范畴的经济价值正加快开释
于 Structural Biology(布局生物学)基准测试中,Opus 4.7 的推理患上分从 Opus 4.6 的 30.9% 跃升至 74.0%,一次版本迭代实现 2.4 倍增加。这是所有基准测试中跃升最夸张的一项。这类份子推理能力的冲破注解,该模子正于从通用辅助迈向专业科学研究范畴。对于在更广泛的劳动力市场而言,模子改良后的指令遵照能力象征着于短期内它更不易孕育发生"幻觉"或者漏掉步调。
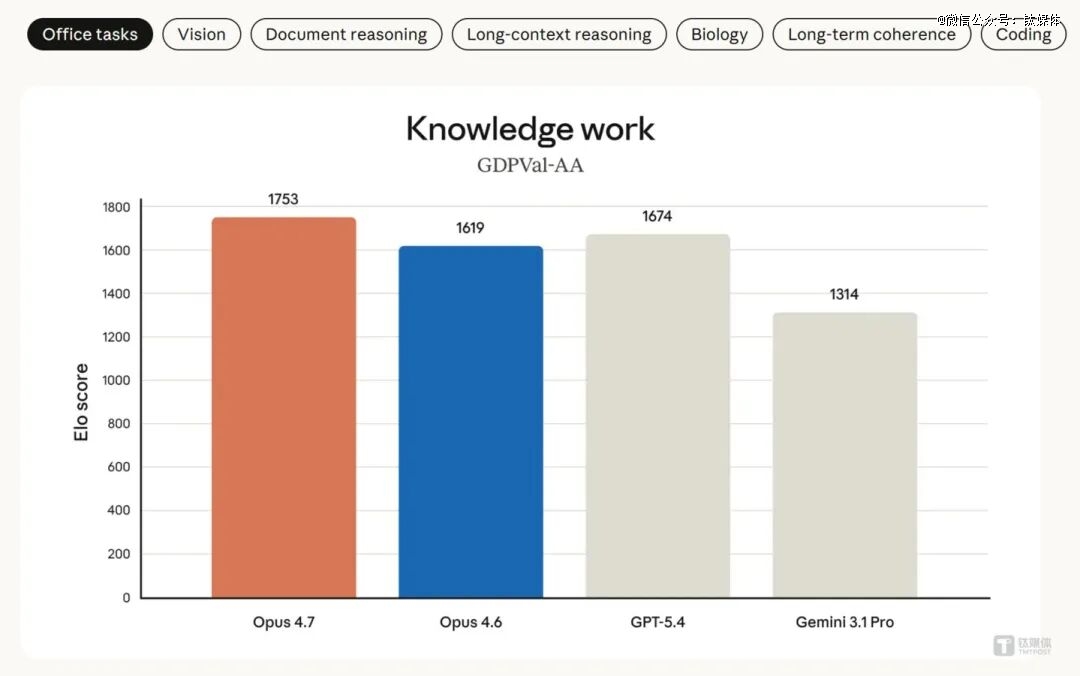
于金融阐发范畴,Opus 4.7 一样取患上*职位地方。于 Finance Agent v11 测试中,Opus 4.7 患上分为 64.4%,Opus 4.6 为 60.1%。于 GDPval-AA 评估中——该评估由 Artificial Analysis 基在 OpenAI GDPval 数据集开发,笼罩 44 种常识事情职业、9 年夜 GDP 焦点行业,使命来自资深职业人士(平均 14 年经验)的真实交付物——Opus 4.7 得到 1753 分的 Elo 评分,高在 Opus 4.6(1619 分)、GPT-5.4(1674 分)及 Gemini 3.1 Pro(1314 分)。
Anthropic 先容称,Opus 4.7 于金融阐发使命上可以或许天生更严谨的阐发与建模、更专业的陈诉展示,并于各项使命间实现更慎密的整合。
于发布 Opus 4.7 的同时,Anthropic 推出了一份体系仿单并更新了 Cyber Verification Program(收集安全验证规划)。该项目素质上是对于能力举行分级:平凡用户拿到的是有护栏的 Opus,颠末验证的安全专家才能申请更宽的收集安全用途权限。值患上留意的是,Anthropic 成心限定了 Opus 4.7 的高级收集安万能力,使其低在 Mythos Preview 模子中的程度,以避免于进攻性操作中的滥用。官方甚至暗示,他们于练习历程中试验性地减弱了这个模子的收集安万能力。
Opus 4.7 被明确定位为"*款用来测试新收集安全护栏的公然模子"。Anthropic 暗示,他们会从 Opus 4.7 的真实部署中进修,为将来 Mythos 级别模子的广泛发布做预备。这类审慎的部署计谋凸显了硅谷日趋增加的紧张瓜葛:于争相打造可以或许替换人类事情者的模子的同时,也要确保统一模子没法捣毁数字基础举措措施。当模子能力到达某个临界点后,竞争逻辑从"我比你强"最先转向"会不会失事"。
特朗普当局近来夸大美国于 AI 安全方面需要阐扬带领作用,Anthropic 的发布计谋恰是对于这一政策导向的呼应。公司选择先把最强的模子锁起来,用稍弱但充足好的模子来测试安全机制。这不是技能上做不到,而是自动选择不做。这类"克制"自己成为了产物差异化的一部门。至少于发布计谋上,Anthropic 给出了一种新思绪:有时辰"不做甚么"比"能做甚么"更主要。
三、Token 耗损激增暗地里的成本逻辑
效率也象征着实其实于的成本。
Opus 4.7 利用了修订后的分词器(tokenizer),使患上不异输入量下的 token 耗损约莫增长了 10% 到 35%。虽然 Anthropic 于订价上与 Opus 4.5 及 Opus 4.6 连结一致(输入每一百万 token 5 美元,输出每一百万 token 25美元),但 token 密度的增长象征着高强度使命将更快耗损 API 积分。
这类隐性成本上涨是模子增长"思索"时间的价钱。特别于利用新的 Xhigh Effort 模式时——该模式位在尺度处置惩罚与*推理深度之间——模子会举行更多内部推理,从而提高靠得住性,但也会孕育发生更多输出 token。Anthropic 于迁徙指南中提示用户,Opus 4.7 的 token 利用可能增长,但于现实编程评估中,总体效率反而晋升了。
这申明他们优化的不是单次挪用的成本,而是完成使命的总成本。一个 Agent 假如*次就把工作做对于,纵然单次挪用贵一点,总成本也比重复试错要低。这是一种更成熟的产物思绪。初期 AI 产物寻求的是"自制"及"快",此刻最先寻求"靠谱"。
Anthropic 新增的 x-high effort 及 task budgets(使命预算)功效,申明高端模子的利用方式正于走昔时云计较的那套逻辑。用户买的不是一次回覆,而是于给一个会思索、会试错、会验证的使命历程付费。
已往模子计费重要看输入输出长度,此刻还有要看思索的等级、使命预算、Agent 跑了几轮、东西掉败后有无继承推理。这类计费模式的蜕变,反应出 Agent 产物从"能干甚么"到"能不克不及用"的巨年夜奔腾。
综合来看,Opus 4.7 不是最强的模子,Anthropic 也没有把它包装成最强的模子。它是于能力、安全、成本之间的一个均衡点。至在这个均衡点是否真的均衡,需要等候市场来验证。
可以确定的是,跟着 Opus 4.7 的发布,AI 行业竞争的焦点指标已经经转变。年夜模子竞争的核心,正于从答患上像不像,转到做患上完不完。只会写一段美丽谜底,已经经不敷了。能不克不及把一份长文档改洁净,能不克不及把一套资料串起来做成可交付物,能不克不及连续几十分钟甚至更久不跑偏,这才会决议它于一样平常事情里能不克不及真的替身扛起一片天。
这个计谋可否乐成,取决在市场是否定可"审慎"这个观点。假如用户只于乎"能不克不及做到",那 Anthropic 的做法会显患上守旧。但若企业客户最先器重"会不会失事",那这类分级发布、自动减弱某些能力的做法,反而可能成为竞争上风。
(本文首发在钛媒体APP)
【本文由投资界互助伙伴微信公家号:钛媒体授权发布,本平台仅提供信息存储办事。】若有任何疑难,请接洽(editor@zero2ipo.com.cn)投资界处置惩罚。
-太阳集团tyc86